🔥 Thoughts About Apple's M1 Processor
Over the weekend, I looked into Apple’s M1 processor that’ll power its desktop/laptop offerings. Below are some of my initial thoughts.
Non-Technical Take-Aways:
- It’s an excellent development to have some decent competition for x86 architecture in the desktop/laptop space even though Apple isn’t going to allow its use in non-Apple hardware.
- The trend towards specialized processing units will continue and further pick up speed since the single-threaded CPU performance has been relatively flat for a long time now. The only way to get better performance is either more cores (which comes with high coordination costs and doesn’t work for many workloads) or dedicated hardware for specific tasks.
- ARM is going to make significant in-roads into the server and cloud markets primarily due to its power efficiency. We already see it with Graviton, TPUs, and the dominating trend of ASIC/FPGAs in the HPC market and smart-factories.
Technical Thoughts
It looks like Apple has managed to increase the pipeline width significantly, which means that the M1 has much better IPC than other current CPUs. So it should be able to get better single-threaded performance than most CPUs except for the ultra-high clock speed CPUs from AMD/Intel (of course, all depending on the specific workload). For highly parallel workloads, I guess that the higher-end AMD/Intel CPUs may still have an edge because the M1 has only four high-performance cores (the other 4 are low power ones, i.e., basically a big.little architecture).
To put things in perspective, below is Intel’s Sunny Cove Core as presented in Hot Chips 2020. 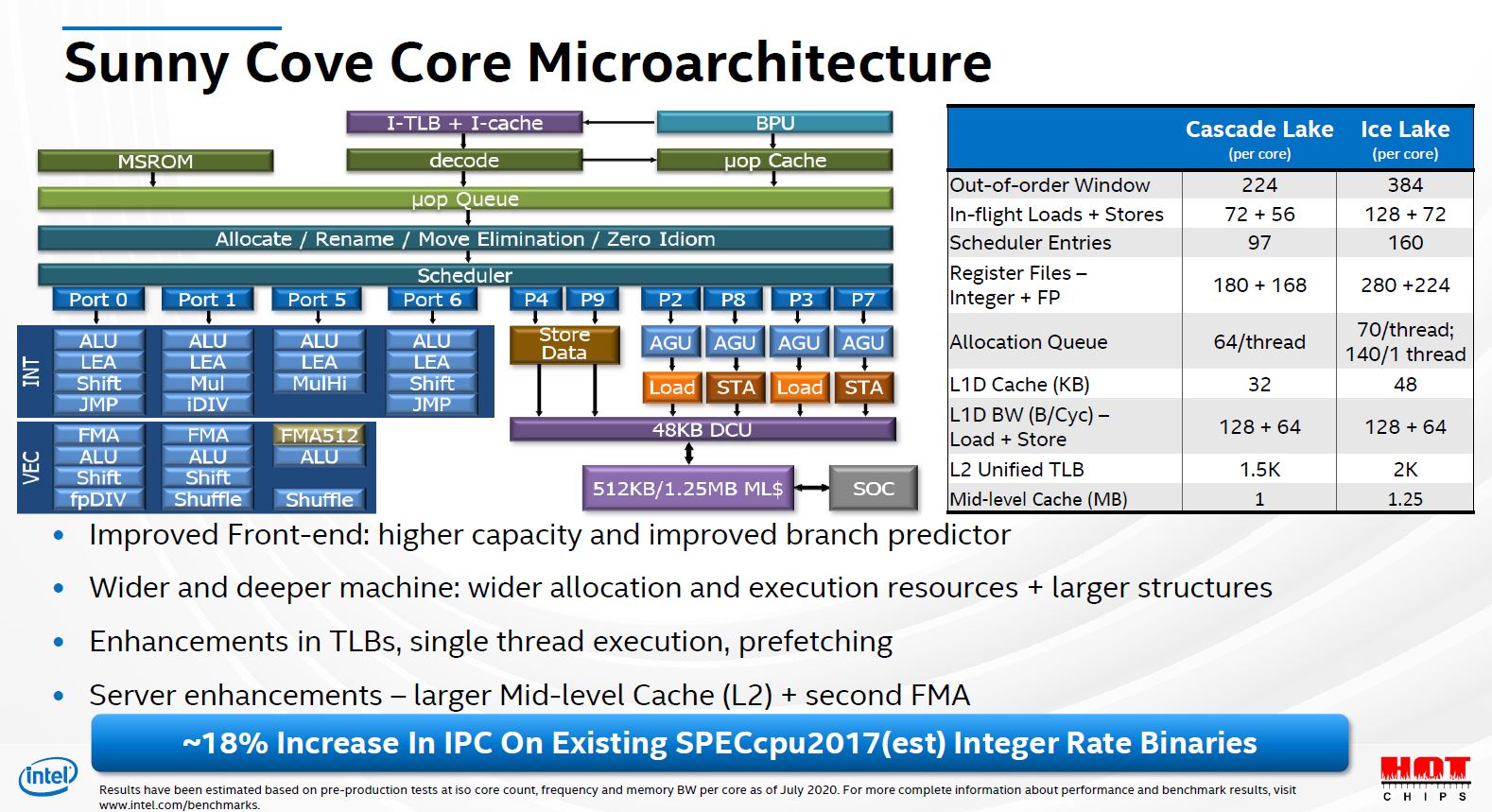
And below is Apple’s M1 micro-architecture for comparison.
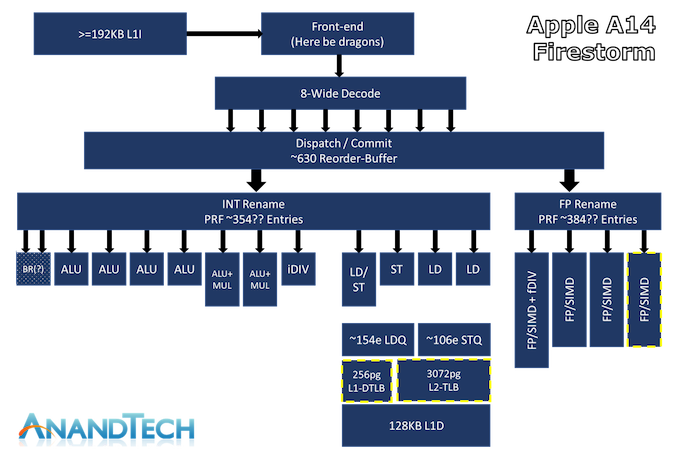
M1 has a much wider decoder but since its RISC (ARM64) so its effective issue width is probably comparable to Sunny Cove’s (x86 CISC). However, the most meaningful bit is the different in the ROB size. M1 is capable of a whopping 630 entries compared to Sunny Cove’s 352 (its probably effectively around 450+ given its ability to executed fused load/stores). This is a significant performance win. Also, M1 is being developed on TSMC’s leading node (5nm) and Intel is a full generation behind in terms of its fab cycle (Icelake would be 7nm).
Getting such a high IPC is indeed an impressive feat. I think that at least some part of that may also be because it is an ARM CPU. x86 is not a particularly elegant architecture. People always brush that aside by saying that internally x86 CPUs also operate like RISC CPUs. That is undoubtedly true, but that only applies after the decode stage in the pipeline. Instruction decoding is still a bottleneck, and without a high decode throughput, even if the rest of the pipeline was extra-wide, it may not be able to get fully utilized. M1 being an ARM CPU, has a much easier decode problem, so they have made an 8 instruction wide decoder compared to the best of 4 on x86 CPUs. Another architectural constraint that probably helps ARM is the memory consistency model. Although x86 doesn’t have a fully sequential consistency model, it is still reasonably strict comparatively. Most RISC CPUs, including ARM and POWER, etc. have significantly more relaxed memory consistency models, allowing the CPU to have much more instructions in flight and this is really where the 630 entries wide ROB is the true win.
Conclusion
Intel still does have an advantage in the single thread performance due to higher clock frequency as well as its dominance in the enterprise workloads but M1 allows Apple to bridge the performance gap by integrating Neural & IO engines on the SoC as well as employing the binary translation to opportunistically optimize certain workloads.
I 100% expect other large silicon comsumers (Cloud providers) to follow suite and roll out their own silicon chips mostly for cost reasons (remember: Intel’s margin is around 50%). I’ll probably write about it someday in future.